
TL;DR
Eu construí um sistema de lead scoring que ingere três famílias de sinais para cada lead no pipeline: dados comportamentais (visitas ao site, visualizações da página de preços, solicitações de demonstração), engajamento por e-mail (cliques, aberturas, descadastros) e dados firmográficos (cargo, tamanho da empresa, status de tomador de decisão). Ele combina esses sinais em uma probabilidade de conversão e classifica cada lead em um dos quatro tiers de ação: Hot, Warm, Nurture e Suppress. O sistema é construído com Python, FastAPI e Streamlit, e roda em produção por uma fração do que ferramentas como HubSpot ou Pipedrive cobram — entregando capacidades que elas não oferecem de fábrica.
O Problema
O time de vendas começa a semana com 200 leads. Alguns vieram da página de preços. Alguns baixaram um whitepaper há seis meses. Alguns participaram de um webinar. Alguns são tomadores de decisão em empresas que se encaixam perfeitamente no ICP. A maioria não.
Sem um sistema, o padrão é a intuição e quem gritou mais alto por último. Os representantes passam a segunda-feira atrás de leads que não abriram um e-mail em semanas, enquanto o prospect que visitou a página de preços três vezes este mês espera até quinta-feira — momento em que já agendou uma demonstração com um concorrente.
O custo não é apenas negócios perdidos. É o imposto invisível na semana de cada vendedor: tempo gasto com prospects de baixa intenção que nunca iriam converter, enquanto leads de alta intenção esfriam.
A pergunta é simples: e se você pudesse saber, antes de fazer uma única ligação, quais leads valem o tempo do seu time?
O que o Sistema Faz
O sistema de lead scoring ingere três famílias de sinais para cada lead no pipeline: dados comportamentais (visitas ao site, visualizações da página de preços, solicitações de demonstração), engajamento por e-mail (cliques, aberturas, descadastros) e dados firmográficos (cargo, tamanho da empresa, status de tomador de decisão). Ele combina esses sinais em uma probabilidade de conversão e classifica cada lead em um dos quatro tiers de ação:
- Hot — ligar em até 2 horas
- Warm — fazer follow-up em até 24 horas
- Nurture — contato semanal, sem urgência
- Suppress — remover do pipeline ativo
Crucialmente, cada lead pontuado vem acompanhado de uma explicação em linguagem simples: os três principais motivos pelos quais ele pontuou alto e quaisquer fatores de risco que o puxam para baixo. Os representantes de vendas não recebem apenas um número — recebem contexto. Um representante que entende por que um lead é hot tem muito mais chances de confiar no sistema e agir sobre ele do que alguém que recebe uma pontuação opaca sem nenhuma justificativa.
Os Resultados
Os números mostram claramente o business case:
Leads Hot + Warm representam apenas 38% do pipeline — mas capturam 64% de todas as conversões.
Detalhando por tier:
| Tier | Participação no Pipeline | Taxa de Conversão | Conversões Capturadas |
|---|---|---|---|
| Hot | 12% | 58,5% | 27% |
| Warm | 26% | 36,2% | 37% |
| Nurture | 39% | 18,5% | 28% |
| Suppress | 23% | 8,2% | 7% |
O tier Hot converte a mais do que o dobro da taxa de referência geral. Os 20% principais dos leads pontuados capturam mais de 50% de todas as conversões.
Uma equipe de vendas seguindo este sistema poderia focar em menos da metade dos seus leads e ainda assim alcançar quase dois terços dos negócios. Isso não é uma melhoria marginal de eficiência — é uma mudança estrutural na forma como o time opera.
O tier Suppress é igualmente valioso. Com uma taxa de conversão de 8,2%, gastar tempo ativo de vendas nesses leads é comprovadamente um desperdício. O sistema não apenas diz para quem ligar — diz para quem parar de ligar.
Como Funciona
Dados e Engenharia de Features
O modelo é treinado em 33 sinais distribuídos em três famílias. Sinais comportamentais — visitas à página de preços, solicitações de demonstração, engajamento com trial — têm o maior peso porque são os mais difíceis de falsificar e os mais preditivos de intenção. O engajamento por e-mail é incluído, com cliques tendo peso maior do que aberturas: cliques exigem ação deliberada; aberturas podem ser acidentais ou disparadas automaticamente por clientes de e-mail.
Sinais firmográficos (flag de tomador de decisão, tamanho da empresa, cargo) fornecem contexto. Um dos achados mais interessantes da etapa de engenharia de features: um tomador de decisão que visitou a página de preços recebe um multiplicador bônus — o efeito de interação entre esses dois sinais é mais preditivo do que cada sinal isoladamente.
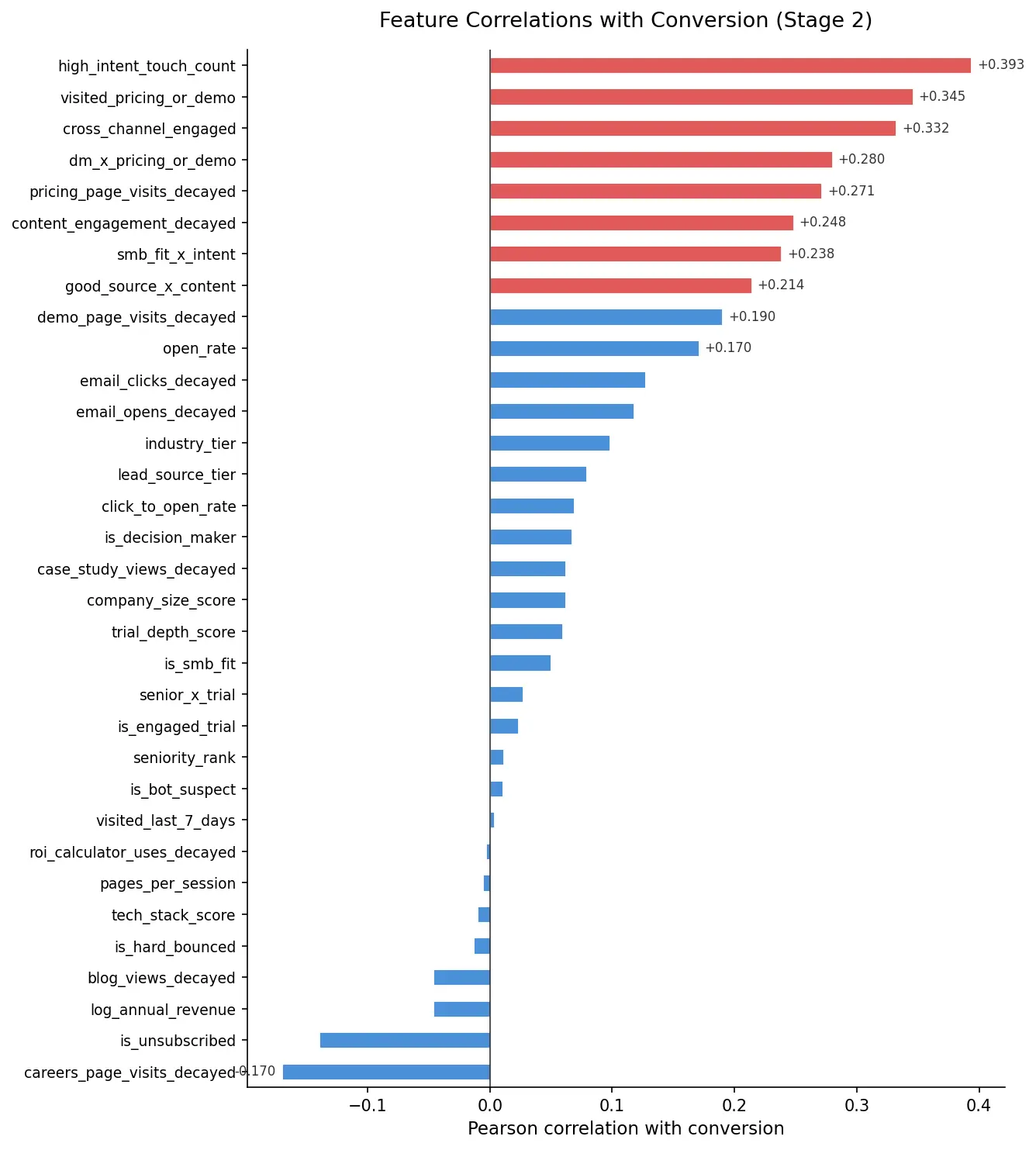 Matriz de correlação dos 33 features
Matriz de correlação dos 33 features
Baseline Rule-Based
Antes de treinar qualquer modelo de ML, construí um sistema de regras artesanal a partir dos mesmos 33 sinais — atribuindo pesos em pontos para cada sinal com base em sua correlação com a conversão, com penalidades assimétricas para sinais negativos como descadastros (–20 pontos) e visitas à página de carreiras. O objetivo era estabelecer uma baseline crível: algo que um especialista de domínio realmente construiria e lançaria.
O resultado foi AUC 0,739 — bem acima do aleatório (0,50) e já bom o suficiente para ser útil. Leads Hot + Warm sob o sistema de regras capturaram 64% das conversões, e o tier Hot sozinho converteu a 58,5%. Isso importou por duas razões: validou que a estrutura de sinais subjacente nos dados era forte, e estabeleceu uma barra significativa para a camada de ML superar.
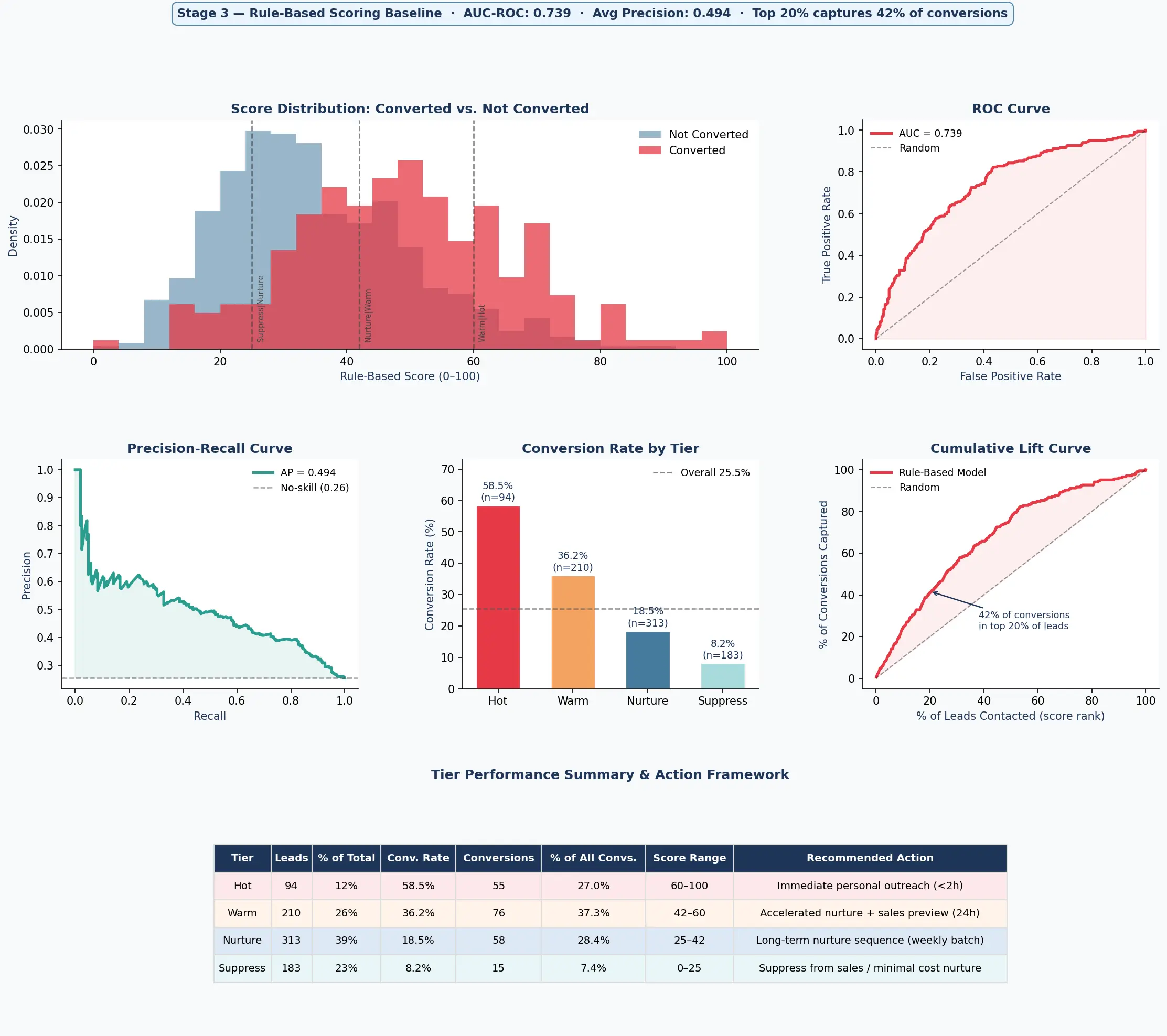 Performance do baseline rule-based
Performance do baseline rule-based
Modeling
Com o baseline estabelecido, dois modelos foram treinados e comparados diretamente: Regressão Logística e Random Forest, avaliados com validação cruzada de 5 folds para produzir métricas honestas fora da amostra.
A Regressão Logística venceu (AUC 0,789 vs. 0,777). O motivo é o tamanho do dataset: com 800 leads, um modelo linear bem regularizado generaliza melhor do que um ensemble de árvores que precisa de mais dados para explorar de forma confiável interações não lineares. Mais complexidade no modelo nem sempre é melhor — precisa ser justificada pelos dados. O modelo em produção é o mais simples.
Como referência, um sistema de regras construído manualmente antes de qualquer ML alcançou AUC 0,739. A camada de aprendizado de máquina adiciona ganho significativo, mas o sistema de regras sozinho já era muito melhor que o aleatório — o que significa que a estrutura de sinais nos dados é forte.
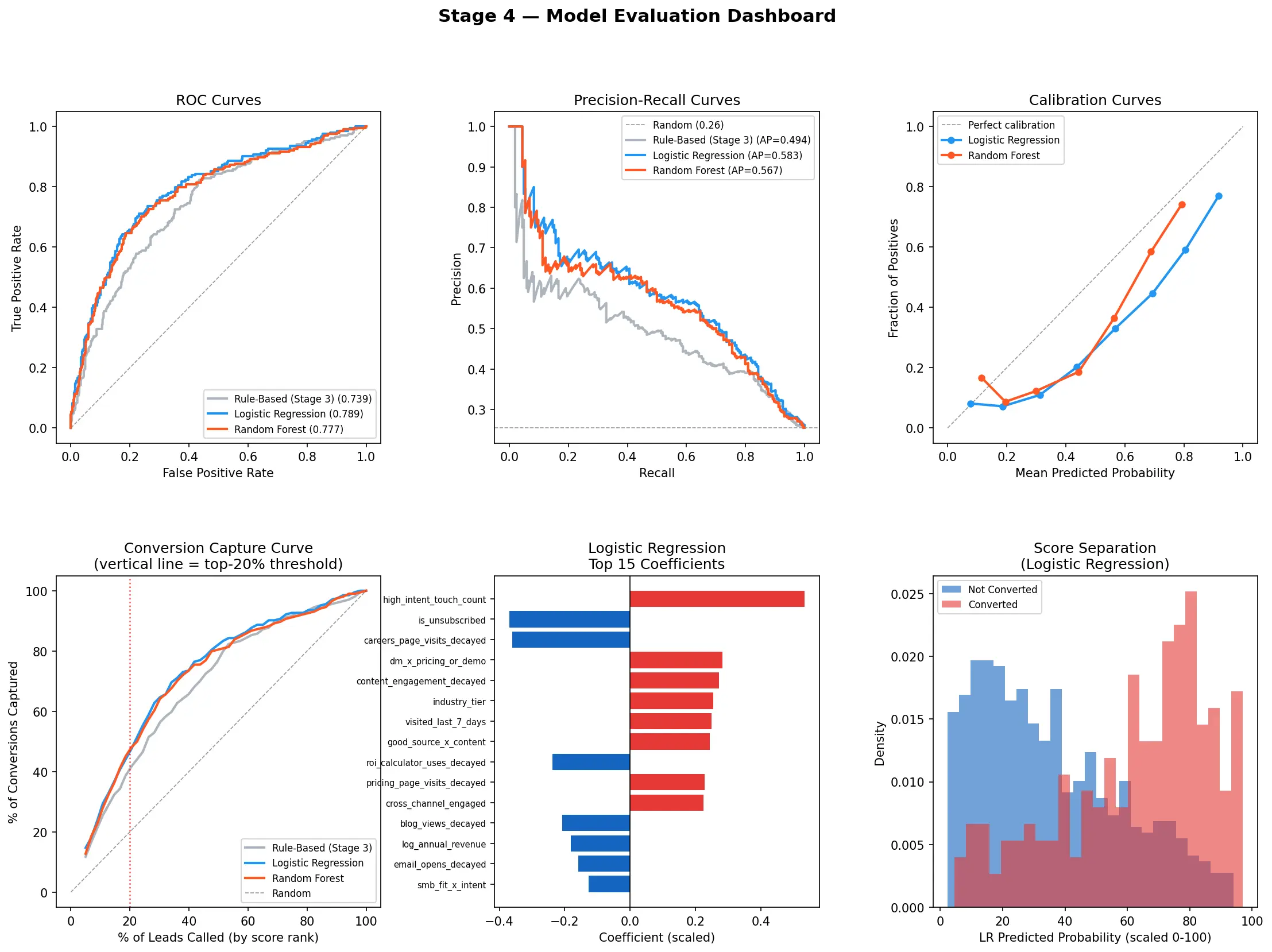 Dashboard de avaliação. Baseline vs ML models
Dashboard de avaliação. Baseline vs ML models
Explicabilidade
Os valores SHAP (SHapley Additive exPlanations) são calculados para cada lead no momento da pontuação. Cada saída inclui os principais sinais positivos que impulsionam a pontuação e quaisquer sinais negativos que a suprimem — apresentados em linguagem simples, não como valores de coeficientes.
Isso importa para a adoção. Um sistema que produz pontuações sem explicação cria atrito: os representantes questionam, os gestores substituem, e o valor de negócio se deteriora. Explicabilidade não é um diferencial — é um pré-requisito para um sistema de scoring que realmente seja utilizado.
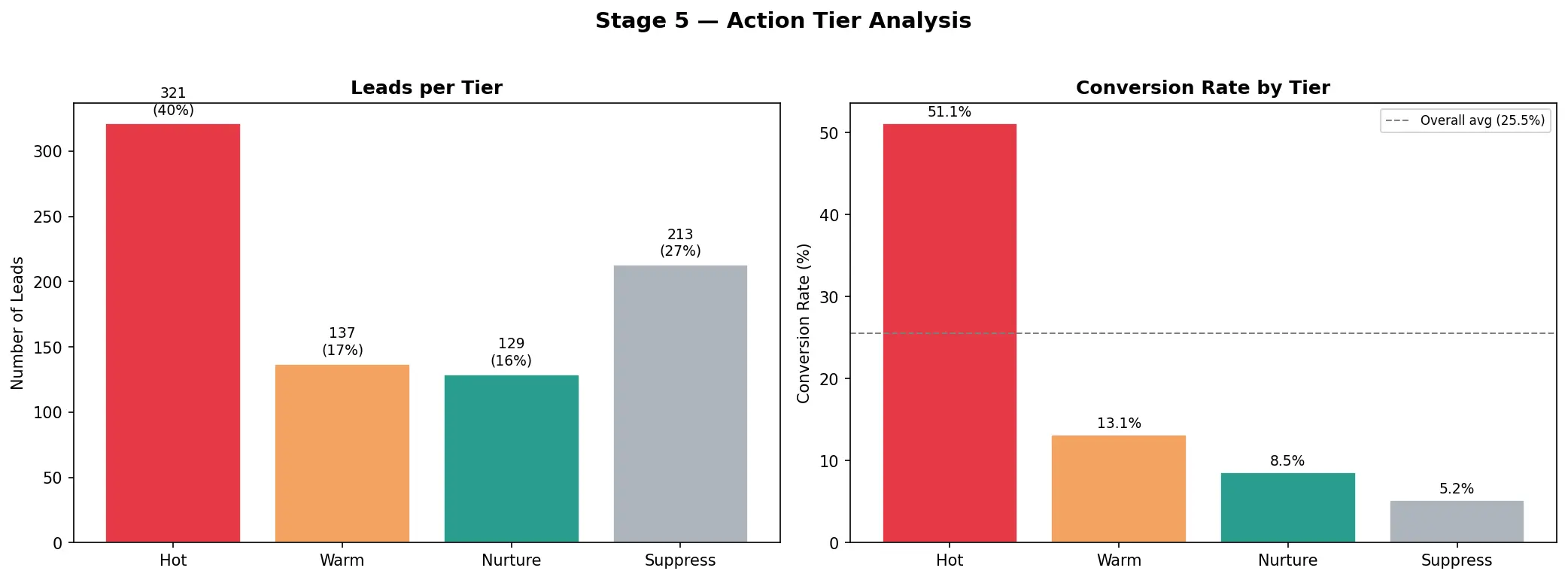 Análise de tiers. Distribuição de pontuações por tier
Análise de tiers. Distribuição de pontuações por tier
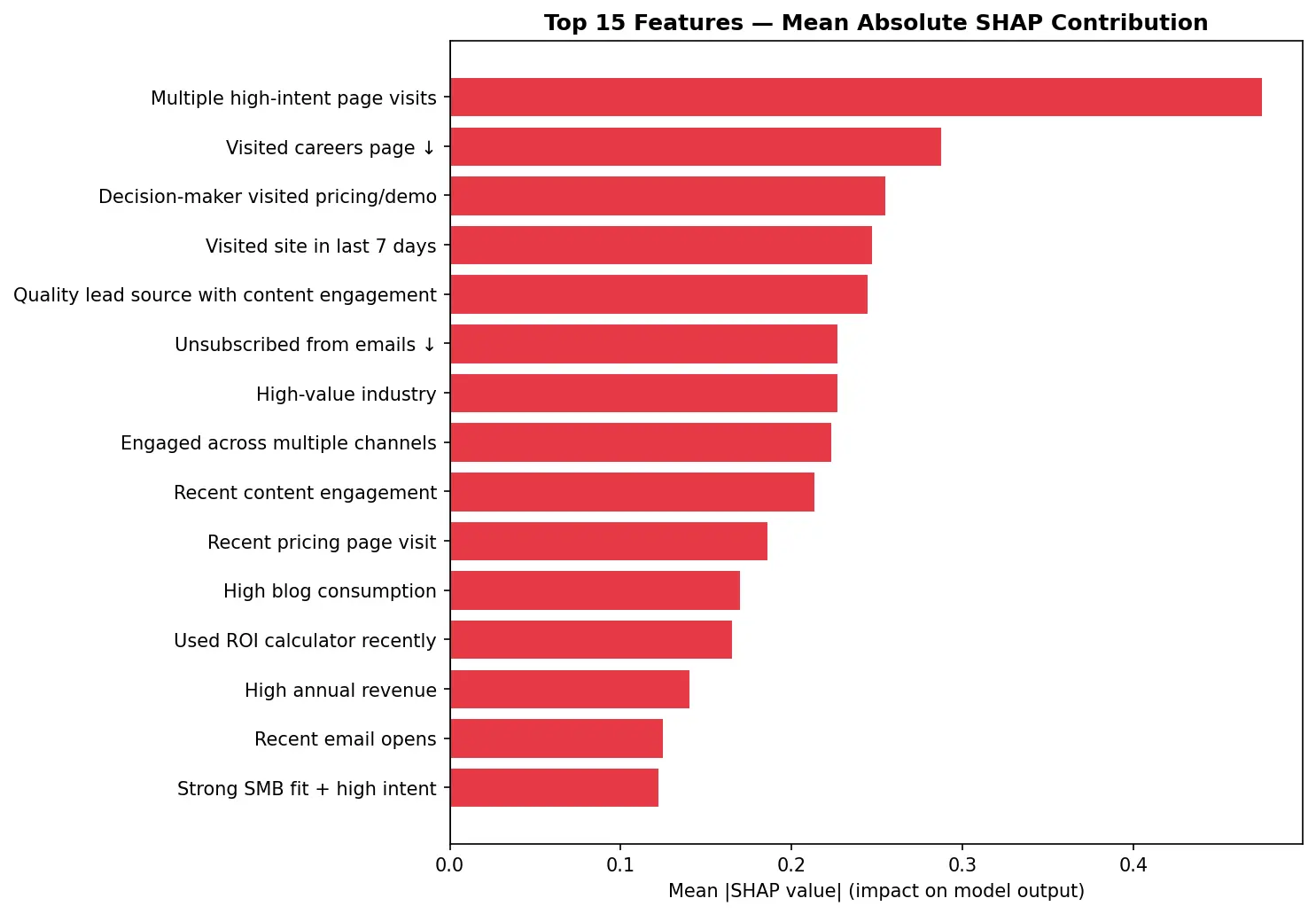 Importância SHAP. Top 15 features e o impacto na pontuação
Importância SHAP. Top 15 features e o impacto na pontuação
Stack Tecnológica
- Python / scikit-learn / SHAP — modelagem, calibração e explicabilidade por lead
- FastAPI — API de produção com endpoints de pontuação individual e batch via CSV
- Streamlit — dashboard interativo para explorar leads pontuados e simular novos
- Docker + GCP Cloud Run — containerizado, implantado e com auto-scaling
- Cloud Scheduler — execuções semanais automáticas de pontuação, sem intervenção manual
O sistema roda em produção por uma fração do custo de ferramentas como HubSpot ou Pipedrive — e entrega capacidades que elas não oferecem nativamente.
Quer transformar leads em oportunidades?
Se o seu time está gastando tempo com leads sem saber quais valem a pena, esse é um problema com solução.
- Veja o código — Repositório no GitHub
- Vamos conversar — Contato